
Creating a Neural Network
- David Raxén

- Jul 2, 2020
- 8 min read
I've played around a bit with machine learning before, mostly using linear regressions and mostly to predict a fairly simple yes/no-question. (Like the predicting survival rates on the classic Titanic data, the one I did using R can be found here -> https://www.kaggle.com/davidraxen/titanic-2-this-time-it-s-r for instance)
But after seeing a video from my favourite content creators on youtube, Crash Course, on AI I got inspired and thougth I'd give it a try to create my own neural network. (The video for the lab in question can be found here: https://www.youtube.com/watch?v=6nGCGYWMObE&t=374s)
The aim here is to create a neural network that can turn handwritten letters into one's and zero's (that represent the same letters ;-) )
To do this I'm using supervised learning (https://en.wikipedia.org/wiki/Supervised_learning) where I'm training a model using input data that has been labeled with it's corresponding output. For this particular challenge there is an already defined database called "emnist" - which is a subset for a bigger database called "mnist". *Emnist is a database containing more than 140 000 images of handwritten letters that can, for instance, be used to create a neural network that recognises handwritten text. (https://pypi.org/project/emnist/)
(*Note. To do this - some packages needs to be installed for Python - including the emnist package which I couldn't install using the "conda" way. But I could do it using pip in my anaconda-terminal.)
from emnist import extract_training_samplesFirst I'm going to grab my data from the OpenML website where X will be my images and y will be their labels.
X, y = extract_training_samples("letters")The data consists of information about the size (28x28 pixels which means 784 in total) of a picture and a "greyscale" value between 0 and 255. To instead make each grayscale-value a number between 0 and 1 (which is a bit easier to work with) I'm therefore going to divide all the values by 255. An action called "Preprocessing". I'm also going to use the first 60 000 values as training data and the last 10 000 as testing data.
Lastly I'm going to reshape the images as rows containing information about each of the 784 pixels.
X = X / 255
X_train, X_test = X[:60000], X[60000:70000]
y_train, y_test = y[:60000], y[60000:70000]
X_train = X_train.reshape(60000,784)
X_test = X_test.reshape(10000,784)I can look at the images I've downloaded by using matplotlibs imgshow-function. (For this I could reshape my training data again to the 28x28-format or I could just look at the original X-variable. - to get the right letter I have to add 96 to the Y-value because of how it is formatted.
print("For y[1234] you get: " + str(y[1234]) + ", which is a number." )
print("For chr(y[1234]+96 you get: " + str(chr(y[1234]+96)) + ", which is it's corresponding letter" )which outputs as:
For y[1234] you get: 16, which is a number. For chr(y[1234]+96 you get: p, which is it's corresponding letter
import matplotlib.pyplot as plt #matplotlib is a library that can be used to plot data.lst = [1337,54,12315,54003,460,23654]
for img_idx in lst:
print(chr(y[img_idx]+96))
plt.figure()
img = X[img_idx]
plt.imshow(img)
plt.show()The lines above plots the letters with the index's saved in the list "lst". The output is 6 different images, but I'm only going to show one here.
z

which is a letter labeled: "z".
The next thing to do is to choose an existing machine learning algorithm to create my neural network. For this I'm going to use the multi-layer perceptron neural network (MLP for short) that is included in the python library SKlearn - which I'm going to import here:
from sklearn.datasets import fetch_openml
from sklearn.neural_network import MLPClassifierNext I'm going to create a neural network with 1 hidden layer with 50 neurons and set it to run through the data 20 times and learn how to make good guesses for handwritten letters!

* The basic idea of what a neural network is described pretty good in the crash course video, and some information can be found here: https://en.wikipedia.org/wiki/Neural_network . But the basic idea is that you have an input layer that handles the format of your data (which in this case is the 784 pixels), that data is transformed via 1 or more hidden layers that looks for patterns in the data and then based on these patterns makes an educated guess for the output layer. In this case the output layer consists of 26 english letters.
mlp1 = MLPClassifier(hidden_layer_sizes=(50,), max_iter=20,
alpha=1e-4, solver='sgd', verbose=10, tol=1e-4, random_state=1, learning_rate_init=.1)
#the above is one line
print("Boom! A MLP network has been created!")Next up is to train it and see how well it performs with these input parameters.
mlp1.fit(X_train, y_train)
print("Training set score: %f" % mlp1.score(X_train, y_train))
print("Test set score: %f" % mlp1.score(X_test, y_test))The output will be a loop where it writes out an error rate per iteration:
Iteration 1, loss = 1.06351395 Iteration 2, loss = 0.64844650
etc...
Training set score: 0.886500 Test set score: 0.840800
The actual numbers will vary a bit if it runs more than one time - but they will stay in the same ballpark.
What I'm interested in the most is the "Test set score". Since this is how good it is to guess on data that it hasn't seen before. And ~84% is actually pretty good.
It can get better though! By visualising the data in a confusion matrix I can get a better feel for what it is getting wrong.
y_pred = mlp1.predict(X_test) #saves the predictions for the test data in a list.
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
plt.matshow(cm)
The brighter (the more yellow'er) the square - the better the neural network is to guess at those letters. It's pretty clear that the letter on the 11-mark (which would be the 12th letter since it's counting from 0) is getting the wrong value often. This is not That surprising given that the 12th letter is "l" which isn't all that different from the letter "i".
I can make a list for all the times my network guessed "i" when it actually was "l" by writing a for loop like this:
#See how many times it guessed "l" when it was "i"
predicted_letter = 'i'
actual_letter = 'l'
mistake_list = [] #An empty list to store mistakes
for i in range(len(y_test)):
if (y_test[i] == (ord(actual_letter)-96) and y_pred[i] == (ord(predicted_letter) - 96)):
mistake_list.append(i)
print(str(len(mistake_list)) + " times the neural network predicted " + predicted_letter + " when it was " + actual_letter) #the above is one line
if len(mistake_list) > 5:
print(mistake_list[:5])which outputs:
109 times the neural network predicted i when it was l [121, 223, 226, 243, 301]
I can take a look at these letters too by using a similar for loop as I did earlier:
lst = mistake_list[:5]
for img_idx in lst:
print(chr(y_test[img_idx]+96))
plt.figure()
img = X_test[img_idx]
plt.imshow(img.reshape((28,28)))
plt.show()(I'm only going to display one of the images)
l
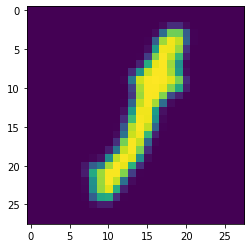
It's understandable that it got i and not l here. But the letters doesn't have the dot over the line. So I can try to add more layers to my neural network to try to make sure that it includes that pattern. (*Note. Adding too many layers will make the network slow and you run the risk of overfitting your model making it Awesome at predicting your training data - but sucky at prediction data it has never seen.)
To make it even better I'm adding some more layers - and this time using 100 neurons per layer. I'm also going to make it run 50 iterations instead of 20.
mlp2 = MLPClassifier(hidden_layer_sizes=(100,100,100,100,100,), max_iter=50, alpha=1e-4,
solver='sgd', verbose=10, tol=1e-4, random_state=1,
learning_rate_init=.1)
mlp2.fit(X_train, y_train)
print("Training set score: %f" % mlp2.score(X_train, y_train))
print("Test set score: %f" % mlp2.score(X_test, y_test))outputs:
Iteration 1, loss = 1.15599672 Iteration 2, loss = 0.54834774
...
Iteration 50, loss = 0.17814713
Training set score: 0.946633 Test set score: 0.886700
It is getting Really good at predicting the training data! And the test set is now getting closer to 90% right as well! This can be tweaked further - but for what I'm doing, this will suffice.
Now! The grand finale! Can my neural network read My handwriting?
I've prepared a couple of images with letters on them. *(Note. At first I tried taking pictures with my phone on letters I'd written on paper - but the background wasn't white enough which made it too difficult for my model - so I drew my letters with the "signature" function on my macbook instead)
To get the images in the right format I'm using the cv2-library and to be able to access files on my computer I'm using the included os-library.
import os
import cv2
import os
path, dirs, files = next(os.walk("path/")) #path is the path to the folder with the images
files.sort()
letters = []
for i in range(len(files)):
img = cv2.imread("path/"+files[i],cv2.IMREAD_GRAYSCALE)
img = cv2.bitwise_not(img) # Inverts the image to match dataset
if img is not None:
letters.append(img)
plt.imshow(letters[2])
I'd say that it's not THAT hard for the human eye to see which letter I've written here. But let's see how the neural network does!
import numpy as np
words = ""
for img in letters:
img = cv2.resize(img, (28,28), interpolation = cv2.INTER_CUBIC) # Change size of image to match 28x28 format
mlp_letter = (np.array(img)).reshape(1,784) # Match format of images to match neural network
pred_letter = mlp2.predict(mlp_letter)
words += str(chr(pred_letter[0]+96))
print(words)which outputs:
frryxtnjia
Which wasn't even close to right! This is because the conversion from an image to the format that the emnist-letter has actually was a bit more complicated then that. The lines above makes the previously shown letter look like this:

And it still kind of looks like an "e".. But for a machine it is note crystal clear. And the letter isn't centered in the picture either - which complicates things even more.
Luckily for me there are instructions for how to make the conversions to better match the emnist data-set. (Which can be read here: https://arxiv.org/abs/1702.05373v1 )
And I've got to admit that this goes a bit over my head!
But to make the images in the right format I have to process them like this:
letters_processed = []
for img in letters:
# First I need to apply a Gaussian blur filter
img = cv2.GaussianBlur(img, (7,7), 0)
# Second and third I need to find the region of interest and center the image.
points = cv2.findNonZero(img)
x, y, w, h = cv2.boundingRect(points)
if (w > 0 and h > 0):
if w > h:
y = y - (w-h) // 2
img = img[y:y+w, x:x+w]
else:
x = x - (h-w) // 2
img = img[y:y+h, x:x+h]
# Fourth is to resize the image to 28x28
img = cv2.resize(img, (28,28), interpolation = cv2.INTER_CUBIC)
# Fifth and finally I need to normailze the pixels and reshape it and add it to the new list
img = img/255
img = img.reshape((28,28))
letters_processed.append(img)
plt.imshow(letters_processed[2])
Now the images looks like this - which actually pretty much looks the same as the images in the emnist-dataset.
So! Let's try out our neural network one more time! - and I am also going to add a bit of code that adds a "space" if the sum of all cells are very low (meaning most/all pixels are a zero - which would mean that the image was a blank)
words = ""
for img in letters_processed:
# -- Checking if letter is a space
pixel_sum = 0
for i in range(28):
for j in range(28):
pixel_sum += img[i,j]
if pixel_sum < 5:
words += " "
# --------
else:
mlp_letter = (np.array(img)).reshape(1,784) # Match format of images to match neural network
pred_letter = mlp2.predict(mlp_letter)
words += str(chr(pred_letter[0]+96))
print("And it all adds up to:")
print(words)which outputs to:
And it all adds up to: cheljej fc
Which isn't perfect! But maybe it's good enough for you to see what I had written? A hint could be that it's a sports team that should've had their defence better sorted out yesterday!
I hope you learned something! I sure did!



Comments