
Revisiting my old twitter analysis (And finding out I've gotten better!)
- David Raxén

- May 3, 2020
- 3 min read
A couple of months ago, 10 according to the analysis(!), I made kernel on Kaggle where I used my own tweets as input data. The kernel can be found here: https://www.kaggle.com/davidraxen/twitter-analysis-screaming-into-the-void
What I set out to do was a Wordcloud image and I thought that the twitter data would be a good way to make it personal.
Your twitter data can easily be downloaded by following these steps: https://help.twitter.com/en/managing-your-account/how-to-download-your-twitter-archive
and comes in a .js-format that I had great difficulty to make something of and I spent hours and hours googling how to make it useful by using the json-module in Python. I asked some old friends who studied programming back at the university but I still came up short.
What I ended up doing was creating a .txt-file by opening the .js-file and copying most of it into notepad and then reading that file instead. - Something that I did not feel great about ;-)
I've gotten back into twitter big time since the Covid-19 situation started and I wanted to see if my twitter analysis would say something more interesting this time! It turns out: No. I'm still screaming into the void.
But I noticed that I would tackle some of the situations a bit differently when looking at it again a couple of months later and the new analysis came to look like this:
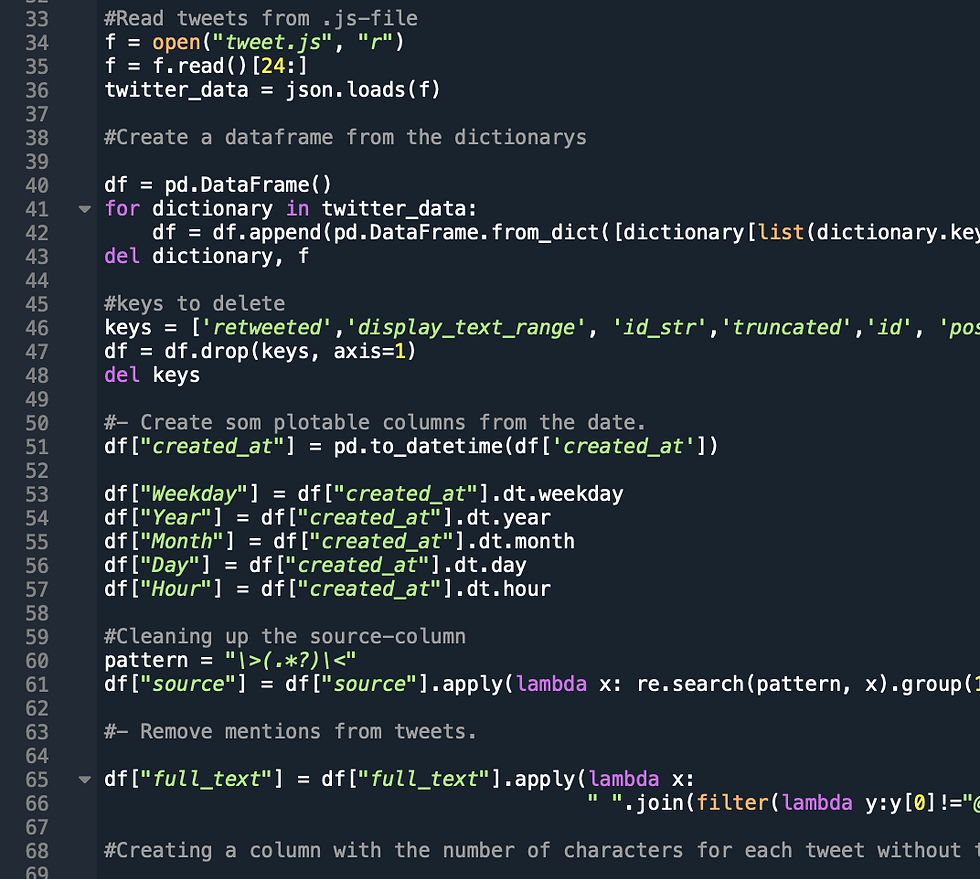
Upon revisiting it yesterday it took me a couple of minutes before I figured out how to get my data from the original .js-file. And to my disappointment it didn't need to be more complicated than this:
#Read tweets from .js-file
f = open("tweet.js", "r")
f = f.read()[24:]Looking back on it I can't believe I couldn't figure out that the ".read()" part was what I needed to include to create my string from the "<_io.StringIO object at 0x15340e828>" that I got from opening my js-file.
It became evermore clear that I actually have picked up a thing or two when I looked at the way I cleaned my data the first time. For example I handled the "date" column like this:
#- Split dates.
A = df["created_at"].str.split(" ", expand = True)
A = A.drop(4, axis=1)
AHeaders = ["Year", "Month", "Day"]
A.columns = ["Weekday", "Month", "Day", "Time", "Year"]
df = pd.concat([df, A], axis=1)
df = df.drop("created_at", axis=1)
del A
del AHeadersWhich is fine . I can totally follow what I did and why I did it - but compared to how I handled the same problem a couple of months later:
#- Create som plotable columns from the date.
df["created_at"] = pd.to_datetime(df['created_at'])
df["Weekday"] = df["created_at"].dt.weekday
df["Year"] = df["created_at"].dt.year
df["Month"] = df["created_at"].dt.month
df["Day"] = df["created_at"].dt.day
df["Hour"] = df["created_at"].dt.hourI feel that this is more than a bit more smooth. I toyed around with creating a function for this - that creates a new column based on features (day, month etc.) stored in a list. But I ended up being ok with this!
I also had a snippet that removed the "mentions" from the tweets that looked like this:
#- Remove mentions from tweets.
for words in df["full_text"]:
ssplit2 = ""
ssplit = words.split()
for word in ssplit:
if word[0] == "@":
word = ""
else:
ssplit2 = ssplit2 + " " + word
if ssplit2[0] == " ":
ssplit2 = ssplit2[1:]
else:
ssplit2 = ssplit2
df.loc[df.full_text == words, "full_text"] = ssplit2
del words
del ssplit2
del ssplit
del wordAgain, it works - but it's a bit long and I felt that there probably is an easier way to do this. And indeed there was!
It turns out that it's possible to use lambda functions within lambda functions and I managed to remove both the mentions And the url's from the tweets using only one line - that I spread out over three lines!
#- Remove mentions and links from tweets.
df["full_text"] = df["full_text"].apply(lambda x:
" ".join(filter(lambda y:y[0]!="@" and y[0:4]!="http", x.split())))Worth noting here is that I probably would've had a hard time understanding how these lambda functions worked the first time - which means that the first approach probably was better at the time.
I also managed to get out more information overall this time. For instance the column named "entities" contains a couple of nested dictionaries. And using what I've learned I created a function that I could use as a lambda function to pull out the username that was connected to the in_reply_to_screen_name to make for a graph that became a bit more personal!
Turns out learning stuff makes you learn stuff! Who would've thought?



Comments